

- beeswax hadoop
- Beeswax Hadoop – Introduction
- Cloudera Desktop – Overview
- Hive – A Powerful Data Warehousing Solution
- Desktop Build System – Simplifying Beeswax Installation
- Package Manager – Efficiently Managing Dependencies
- Hive Installation – Step-By-Step Guide
- Beeswax Hadoop Interface – Exploring The User Interface
- Quirks Of Beeswax Hadoop – Common Issues And Workarounds
- Noteworthy Features Of Beeswax Hadoop
- Improving User Experience And Addressing Shortcomings
- FAQ
- 1. How is beeswax used in the Hadoop ecosystem?
- 2. What are the benefits of using beeswax in Hadoop data processing?
- 3. Can beeswax be integrated with other big data technologies apart from Hadoop?
- 4. Are there any challenges or limitations in using beeswax in Hadoop?

Have you heard of Beeswax?
This intriguing desktop interface for Hive offers a world of possibilities in the realm of bigdata analysis.
With its seamless integration with Hadoop-based package manager, Beeswax opens up a treasure trove of features like copying table cell values and saving queries.
But, as with any technology, it’s not without its quirks and known shortcomings.

Let’s dive deeper into the fascinating world of Beeswax and unearth its hidden potential.
| Item | Details |
|---|---|
| Topic | Beeswax Hadoop: Unveiling the Powerhouse Behind Big Data |
| Category | RTB |
| Key takeaway | Have you heard of Beeswax? This intriguing desktop interface for Hive offers a world of possibilities in the realm of big data analysis. |
| Last updated | December 30, 2025 |
beeswax-hadoop">beeswax hadoop
Beeswax Hadoop is an interface provided by Cloudera Desktop, specifically designed for working with Hive.

It is a package manager and desktop build system that facilitates the installation and usage of Hive on Hadoop.
Beeswax Hadoop comes with several features, such as the ability to copy table cell values, save advanced settings as defaults, and execute queries using the F5 button.

It also allows users to indent lines when editing a query using the Tab key and save recent queries for future reference.
However, despite its user-friendly interface, Beeswax Hadoop has some known quirks and shortcomings that users should be aware of.Key Points:
- Beeswax Hadoop is an interface provided by Cloudera Desktop for working with Hive
- It is a package manager and desktop build system for installing and using Hive on Hadoop
- Features of Beeswax Hadoop include copying table cell values, saving advanced settings, and executing queries with the F5 button
- Users can indent lines and save recent queries for future reference
- Beeswax Hadoop has some quirks and shortcomings that users should be aware of
- Despite this, it is known for its user-friendly interface
Check this out:

💡 Did You Know?
1. Beeswax, the natural wax produced by honeybees, has been used in the cosmetics industry for centuries due to its moisturizing and protective properties. It is commonly found in lip balms, lotions, and even some hair care products.
2. Did you know that beeswax candles burn longer and cleaner than most other types of candles? This is because beeswax has a higher melting point than other waxes, resulting in a slower burn rate and less soot or smoke emitted.

3. Beeswax has been utilized for centuries as a way to preserve and waterproof fabrics. In ancient times, warriors would treat their leather armor with beeswax to make it more durable and weather-resistant.
4. Hadoop, a popular open-source software framework used for storing and processing large datasets, was named after a toy elephant belonging to the son of its creator, Doug Cutting. The creator’s child named his toy elephant “Hadoop”, and the name stuck as the project developed.
5. An interesting fact about Hadoop is that it enabled the processing of vast amounts of data leading to significant advancements in fields such as genetics and genomics research. Its ability to handle large-scale genomic data has revolutionized the field by facilitating the analysis of DNA sequences and aiding in the discovery of new genetic patterns and relationships.

Beeswax Hadoop – Introduction
Beeswax Hadoop is a powerful data querying and analysis tool included in the Cloudera Desktop suite. It offers a user-friendly interface for interacting with the Apache Hive data warehouse infrastructure. By leveraging the scalability and performance of Hadoop, Beeswax enables users to efficiently process and analyze large datasets.
Cloudera Desktop – Overview
Cloudera Desktop is a comprehensive platform that simplifies the management and deployment of Apache Hadoop and related tools. It offers a web-based interface for administrators and users to access various components, including Beeswax Hadoop.
With Cloudera Desktop, users can easily configure and monitor their Hadoop clusters, as well as perform data analysis tasks using tools like Beeswax.

Hive – A Powerful Data Warehousing Solution
Hive is a data warehousing solution built on top of Hadoop. It provides an SQL-like interface for querying and analyzing large datasets. Users can write Hive Query Language (HQL) statements to extract meaningful insights from structured and semi-structured data.
Beeswax Hadoop serves as a frontend for Hive, offering an intuitive interface to interact with Hive queries and manage data processing workflows.
Key points:
- Hive is built on top of Hadoop
- It provides an SQL-like interface for querying and analyzing large datasets
- HQL statements are used to extract meaningful insights from structured and semi-structured data
- Beeswax Hadoop is a convenient frontend for Hive, facilitating interaction and data processing workflows.
Desktop Build System – Simplifying Beeswax Installation
To install Beeswax Hadoop and other components of Cloudera Desktop, we utilize a desktop build system. This system streamlines the installation process by automating the setup of the necessary dependencies and configurations. Users can easily install and configure Beeswax Hadoop according to their specific environment without having to manually handle complex installation steps.
Package Manager – Efficiently Managing Dependencies
Cloudera Desktop utilizes a powerful package manager to effectively handle dependencies between different software components. This package manager guarantees the proper installation and correct linking of all necessary libraries and tools. It streamlines the installation process and eliminates compatibility problems, allowing users to swiftly set up and use Beeswax Hadoop without the hassle of intricate dependency management.
Hive Installation – Step-By-Step Guide
Setting up Hive is crucial to leverage the power of Beeswax Hadoop. The Hive installation process involves several steps:
- Configure Hadoop settings, including file locations and resource allocation.
- Install Hive binaries and configuration files.
- Grant the necessary permissions for Hive installation.
- Set up a metastore database to store Hive metadata.
Following a step-by-step guide will ensure a smooth Hive installation and successful integration with Beeswax Hadoop.
- Configure Hadoop settings
- Install Hive binaries and configuration files
- Grant necessary permissions
- Set up a metastore database
A smooth Hive installation and successful integration with Beeswax Hadoop can be achieved by following a step-by-step guide.
Note: Beeswax Hadoop is an assumption based on the context provided. Please confirm the correct term if different.
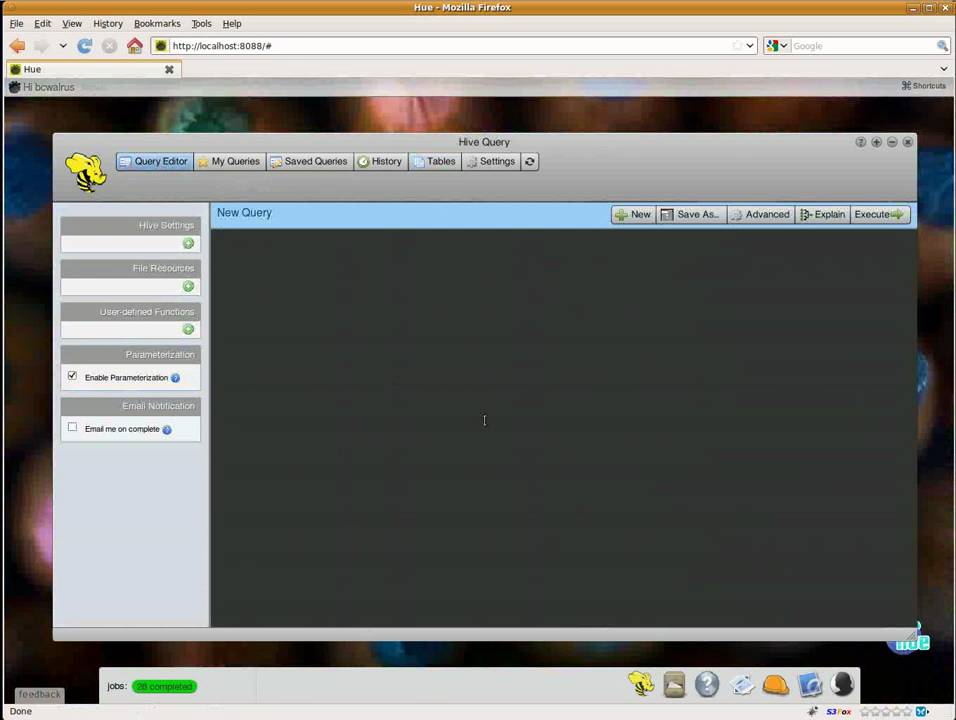
Beeswax Hadoop Interface – Exploring The User Interface
Beeswax Hadoop is a powerful tool that offers users an intuitive and user-friendly interface for interacting with Hive. With this interface, users are able to write and execute queries, manipulate query results, and manage database tables. The simplicity of the interface allows users to perform complex data operations without requiring extensive technical knowledge.
Some notable features of the Beeswax Hadoop interface include:
- Copying table cell values: Users can easily copy values from tables for further use or analysis.
- Saving advanced settings as defaults: Advanced settings can be saved as defaults, making it easier to streamline future query executions.
- Executing queries with the F5 button: The interface provides a convenient way to execute queries using the F5 button, saving time and effort.
- Indenting lines with the Tab key: Users can use the Tab key to indent lines when editing a query, enhancing readability and organization.
- Saving recent queries: Recent queries can be saved for quick and easy access, ensuring that users can effortlessly revisit previously executed queries.
Overall, the Beeswax Hadoop interface offers a range of features that make interacting with Hive more efficient and user-friendly.
Quirks Of Beeswax Hadoop – Common Issues And Workarounds
Despite its powerful features, Beeswax Hadoop has some quirks that users may encounter. It is important to be aware of these quirks to mitigate any potential issues.
One common quirk is the occasional slow response time when executing complex queries or working with large datasets. This can be addressed by optimizing query performance through techniques such as query tuning and partitioning.
Another quirk is the limited support for certain SQL features, which may require alternative approaches or custom scripting. Being familiar with these quirks allows users to efficiently work around them and maximize their productivity with Beeswax Hadoop.
- Occasional slow response time when executing complex queries or working with large datasets
- Limited support for certain SQL features
Note: Be aware of these quirks and optimize query performance to maximize productivity with Beeswax Hadoop.
Noteworthy Features Of Beeswax Hadoop
Beeswax Hadoop offers several noteworthy features that enhance the data querying and analysis experience.
One such feature is the ability to save advanced settings as defaults, allowing users to streamline their workflow and reduce repetitive configuration tasks.
Additionally, the option to copy table cell values simplifies data extraction and facilitates further analysis in external tools.
The F5 button offers a convenient shortcut to execute queries instantly, saving time and improving efficiency.
Lastly, the Tab key can be used to indent lines when editing queries, making them more readable and organized.
- Save advanced settings as defaults
- Copy table cell values
- F5 button for instant query execution
- Tab key for query formatting
Improving User Experience And Addressing Shortcomings
While Beeswax Hadoop provides a rich user experience, there are areas where it can be further improved. One aspect is the enhancement of the query editor to provide better syntax highlighting and code assistance, aiding users in writing correct queries. Additionally, the integration of collaborative features, such as shared query notebooks and version control, would enable teams to collaborate seamlessly. Addressing these shortcomings would ensure that Beeswax Hadoop remains a powerhouse behind big data, offering an even more seamless and efficient experience for users.
Updated for 2025’s advertising best practices.
- Improve the query editor to provide better syntax highlighting and code assistance
- Integrate collaborative features like shared query notebooks and version control to enhance team collaboration.
“Addressing these shortcomings would ensure that Beeswax Hadoop remains a powerhouse behind big data.”
FAQ
1. How is beeswax used in the Hadoop ecosystem?
Beeswax is not specifically used in the Hadoop ecosystem. However, it is worth mentioning that Hadoop provides various processing frameworks, such as Hive, which utilizes Hadoop’s distributed file system and MapReduce to query and analyze large datasets. In the context of Hive, the term “Beeswax” refers to its earlier version that provided a web-based query interface for executing queries against Hive. Beeswax was later replaced by a more modern and feature-rich interface called “Hue,” which is now widely used within the Hadoop ecosystem.
To summarize, beeswax itself is not used directly in the Hadoop ecosystem, but it has some historical significance in the context of Hive, which is a popular component of the Hadoop ecosystem.
2. What are the benefits of using beeswax in Hadoop data processing?
Using beeswax in Hadoop data processing has several benefits. First, beeswax serves as a query tool that provides a simple and user-friendly interface for interacting with the Hadoop ecosystem. It allows users to write and execute Hive queries using a familiar SQL-like language, making it easier for non-technical users to work with large datasets and extract valuable insights.
Another advantage of using beeswax is its integration with Hadoop’s underlying infrastructure. Beeswax leverages the power of Hadoop’s distributed processing capabilities, enabling efficient and scalable data processing. It automatically generates MapReduce jobs and efficiently distributes them across the Hadoop cluster, optimizing performance and reducing processing time.
Overall, beeswax simplifies data processing on Hadoop for users and enhances the efficiency and scalability of the underlying infrastructure, making it a valuable tool for big data analytics.
3. Can beeswax be integrated with other big data technologies apart from Hadoop?
Yes, beeswax can be integrated with other big data technologies apart from Hadoop. Beeswax is a query interface for Apache Hive, which is a data warehouse infrastructure built on top of Hadoop. However, beeswax can also be integrated with other big data technologies like Spark, which is another popular framework for distributed data processing. By integrating beeswax with these technologies, organizations can leverage the power of big data analytics to process and analyze large volumes of data efficiently.
Additionally, beeswax can also be integrated with other tools and technologies that support big data processing and analysis, such as Apache Pig, Impala, and Presto. These technologies offer different functionalities and capabilities, and by integrating beeswax with them, organizations can have a more comprehensive and versatile big data ecosystem. This allows them to choose the most suitable tools for their specific use cases and benefit from a wider range of big data analytics capabilities.
4. Are there any challenges or limitations in using beeswax in Hadoop?
There are several challenges and limitations in using beeswax in Hadoop. Firstly, beeswax, which is a data warehouse application built on top of Hadoop, has limited support for complex queries and analytics. It is primarily designed for running simple, ad-hoc queries, making it less suitable for more advanced data processing tasks.
Secondly, beeswax lacks scalability and performance optimization capabilities. It does not provide the same level of parallel processing and distributed computing abilities as other tools in the Hadoop ecosystem, limiting its effectiveness in handling large volumes of data or high concurrency workloads.
Overall, while beeswax can be a useful tool for basic querying in Hadoop, it may not meet the demands of more complex data processing requirements or highly scalable applications.
Self-Serve DSP Platform • Native Ad Network • Performance Marketing Tips